Gpipe
切分 micro-batch
在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练。未划分前的数据,叫mini-batch。在mini-batch上再划分的数据,叫micro-batch。
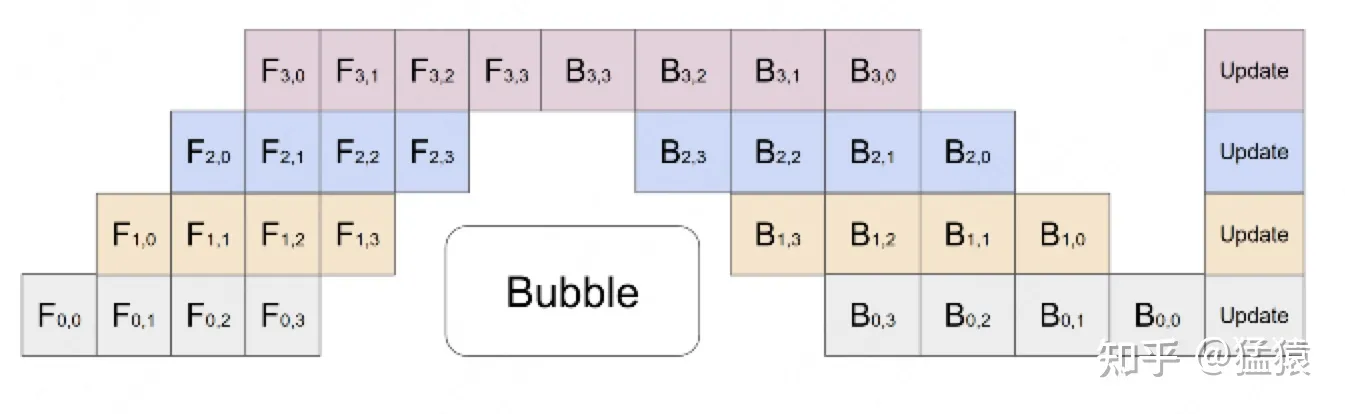
第一个下标表示GPU编号(也表示神经网络的层数),第二个下标表示 micro-batch 编号
通过这种方式解决了 GPU利用度不够 的问题
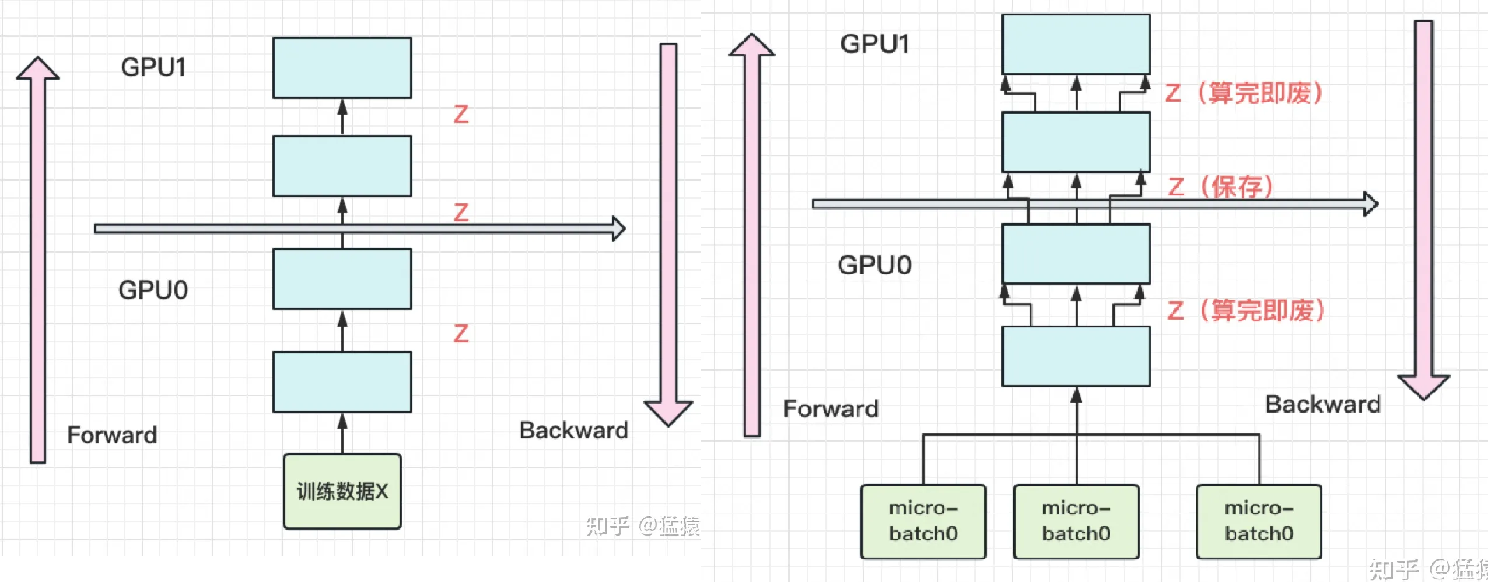
re-materialization(active checkpoint)
随着模型的增加,每块GPU中存储的中间结果也会越大。对此,Gpipe采用了一种非常简单粗暴但有效的办法:用时间换空间,在论文里,这种方法被命名为re-materalization,后人也称其为active checkpoint。
具体来说,就是几乎不存中间结果,等到backward的时候,再重新算一遍forward。
每块GPU上,我们只保存来自上一块的最后一层输入z,其余的中间结果我们算完就废。等到backward的时候再由保存下来的z重新进行forward来算出。
(左图为改进前,右图为改进后)
关于 batch normalization
在micro-batch的划分下,我们在计算 Batch Normalization 时会有影响。Gpipe的方法是,在训练时计算和运用的是micro-batch里的均值和方差,但同时持续追踪全部mini-batch的移动平均和方差,以便在测试阶段进行使用。Layer Normalization则不受影响
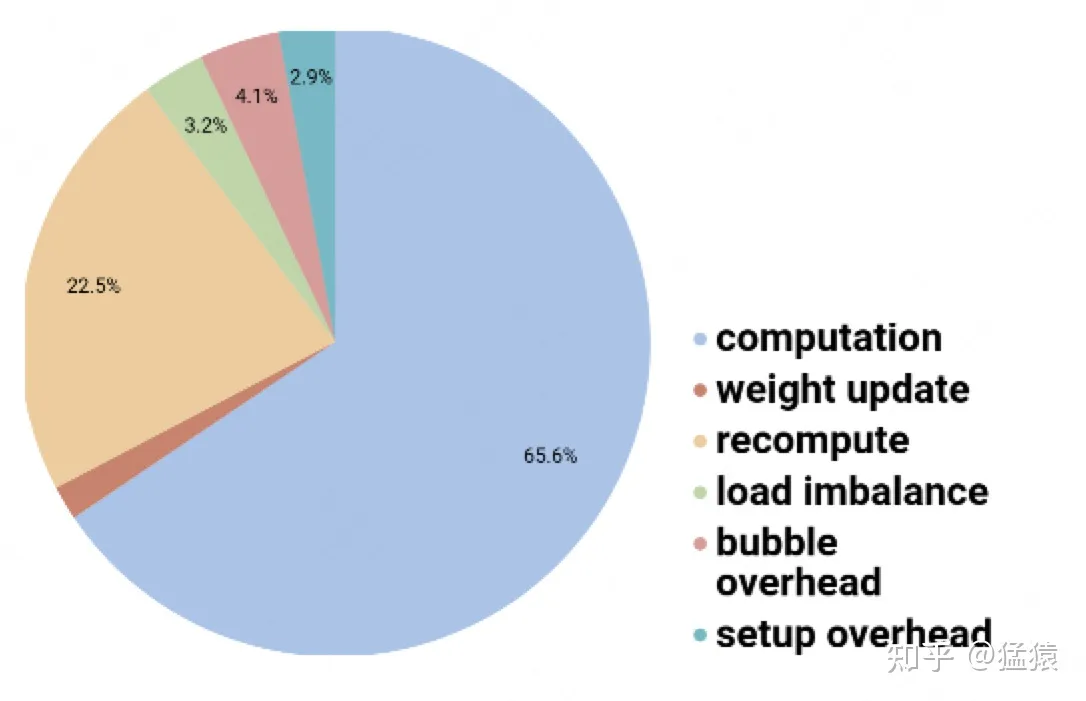
Gpipe 下消耗时间分布