文本预处理
一个简单的例子:
- 读取数据集,忽略标点符号和大小写(也就是说,成的字符串)。
- 词元化(tokenize):将步骤 1 中提到的字符串转化为由单词组成的列表。
一个例子:
源数据:I'm from China.
第1步:i m from china
第2步:["i", "m", "from", "china"]
代码:
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
lines = [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines] # 第1步
token_list = [line.split() for line in lines] # 第2步
(lines 可能有多行,所以对应的 token_list是一个二维的 list )
- 词表:将单词映射到数字索引,便于后续操作。
- 一般来说,很少出现的词元通常被移除
- 可以加入一些特殊的词元(常被称为
reserved_tokens),例如:填充词元(<pad>); 序列开始词元(<bos>); 序列结束词元(<eos>)
词表中常常会统计单词出现的次数(频次) - 最流行的词往往是一些没有实际意义的语法助词,这些词通常被称为停用词(stop words),如:the、i、and、of、a、to、was 等。
- 词频以一种明确的方式迅速衰减。 将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线这意味着单词的频率满足 齐普夫定律(Zipf’s law):第
个最常用的单词的频率 (即 ) - n 个连续单词组成的单词序列出现的频率也满足 齐普夫定律(Zipf’s law)。这使得拉普拉斯平滑非常不适合语言建模。 作为代替,我们将使用基于深度学习的模型。
读取长序列数据
当序列变得太长而不能被模型一次性全部处理时, 我们可能希望拆分这样的序列方便模型读取。在选定的子序列长度确定的情况下,不同的初始位置偏移量会导致不同的数列,例如:

因此,我们可以从随机偏移量开始划分序列, 以同时获得覆盖性(coverage)和随机性(randomness).
实际应用
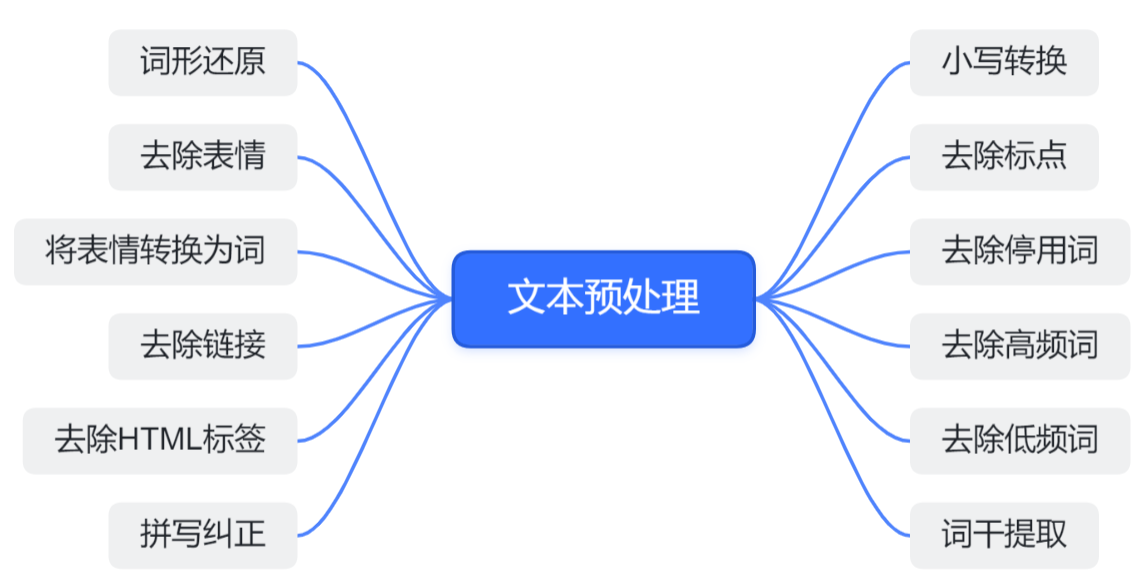
常用的 python 库:
import re # 正则表达式库
import nltk # 自然语言工具包
import spacy # 自然语言工具包
import string
from collections import Counter
from bs4 import BeautifulSoup
from spellchecker import SpellChecker
pd.options.mode.chained_assignment = None
**停用词**就是经常在某种语言中出现的的词语,比如英语中的the,a等等。很多时候,这种词语对我们的任务无法提供有效的信息,所以我们可以把它去掉。下面是利用nltk去除英语中的停用词的实现,你也可以根据任务创建自己的停用词表。
```python
STOPWORDS = set(nltk.corpus.stopwords.words('english'))
def remove_en_stopwords(text):
"""remove english stopwords
"""
return " ".join([word for word in str(text).split() if word not in STOPWORDS])